With the explosive growth of local digital music libraries, automated and intelligent music tag analysis has become a necessity for audiophiles and professional organizers. However, when introducing AI automated tagging, we face a severe engineering challenge: How to guarantee the ultimate depth of analysis while 100% ensuring that the user’s precious original audio files are not contaminated?
In the first phase of architectural evolution, we completely resolved this contradiction by decoupling the Audio Analysis Pipeline and introducing a pioneering Draft System.
I. Dual-Lane Architecture for Audio Analysis
To balance analysis accuracy, performance, and offline availability, we decoupled the analysis tasks at the bottom layer into two independent lanes: pure Digital Signal Processing (DSP) and Deep Learning Inference (ONNX), while maintaining a unified event and state flow at the top layer.
1. AudioMath: Acoustic Parameter Detection via Pure DSP
For detecting BPM, Key/Camelot, and authenticating true/fake HiFi, we utilize the AudioMath lane. This lane operates entirely independent of ONNX models and relies on classical DSP algorithms:
- Performance Advantage: It directly reads the decoded PCM stream of the audio file, calculating energy bursts and autocorrelation in the Rust layer, which saves memory tremendously.
- True/Fake HiFi Authentication: To detect high-frequency cutoffs and fake upsampling, we support dynamic sample rate passthrough at the preprocessing layer, directly analyzing the spectral decay of the audio to avoid errors introduced by resampling.
2. MusicTags: Semantic Classification via ONNX
For abstract semantics like Genre, Mood, and Instruments, we use locally-run deep learning models. Wrapped in a unified audio_analysis long-running task, the model outputs are precisely mapped to the user’s tag set.
[!NOTE]
Both lanes strictly adhere to a zero-network-dependency design, ensuring that all media asset analysis is completed 100% on the edge (locally), meeting extremely high privacy standards.
II. The Pioneering Draft System
Although AI models are powerful, they can never perfectly match a user’s personal preferences 100% of the time. Traditional music management software often directly overwrites audio metadata after analysis, which is highly destructive for users who carefully curate their personal libraries.
To address this, we introduced the SQLite-based Draft System, which is one of the core highlights of our architecture.
The core logic of the Draft System is that whether it’s manual editing, AI analysis, or batch imports, no modification is directly written back to the original audio file. They first generate a digital Patch Plan, acting as a “draft” that is safely stored in an independent, high-performance SQLite database.
Within the workbench, users can seamlessly preview the effects of these drafts. Only when the user completely confirms and actively clicks “Apply Writeback” does the system use an atomic secure write pipeline (writing to a temporary file, replacing it, and retaining a rollback mechanism via a .bak copy) to solidify these tags into the files.
III. Practical Application of True/Fake HiFi Authentication
In the AudioMath DSP lane, True/Fake HiFi authentication is a feature that highly exemplifies the geek spirit of our product.
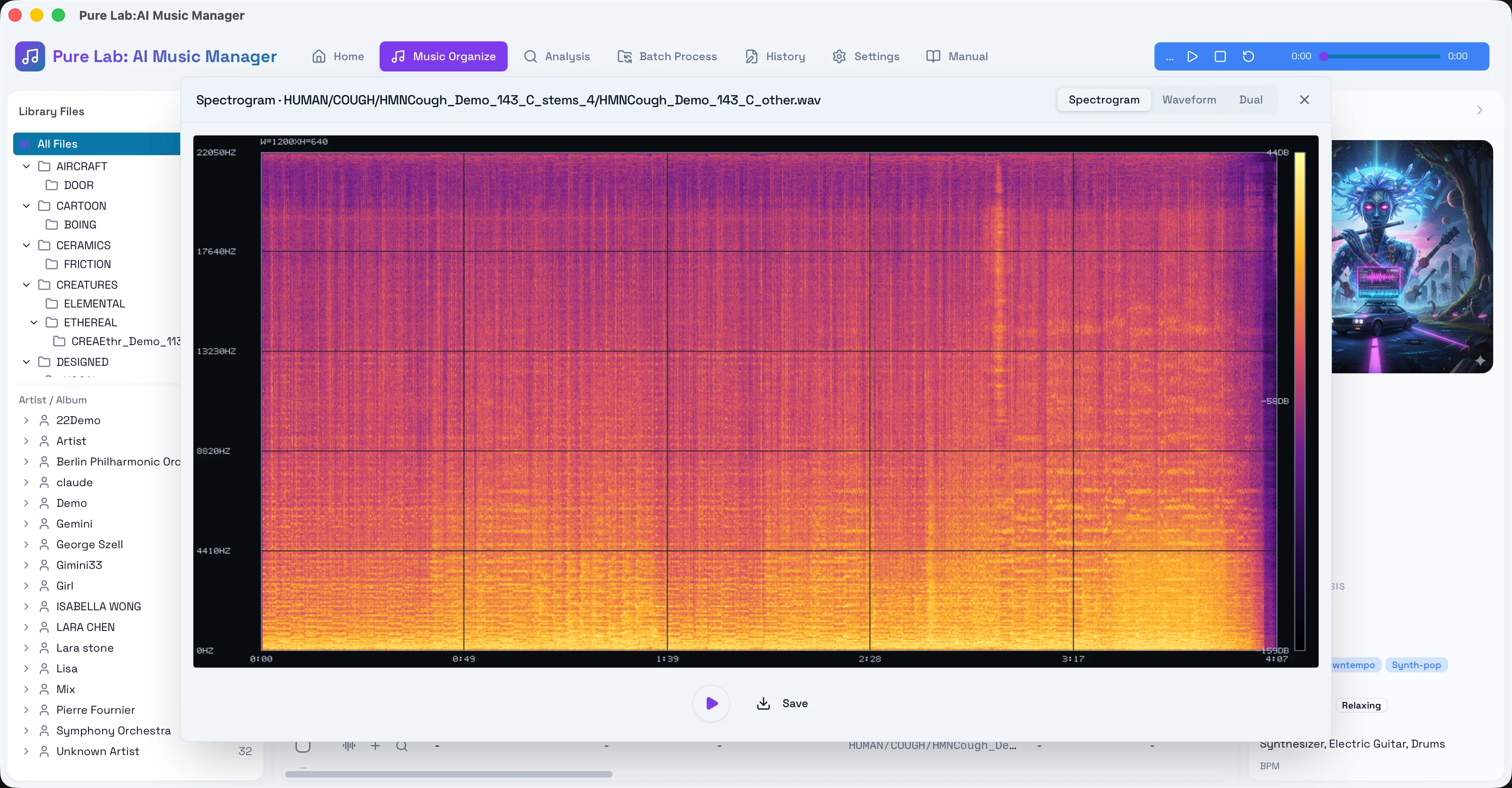
As shown above, when organizing audio, if you encounter a high-res lossless format labeled “24bit/192kHz,” you can directly pull up the spectrum dialog. In the engine’s lower layer, we compute the PURE_QUALITY_CUTOFF_HZ and the corresponding confidence score:
- TRUE_HIRES
- SUSPICIOUS_UPSAMPLING
- SUSPICIOUS_LOSSY
To avoid misjudging original DSDs (high-frequency noise shaping brought by DFF/DSF formats is often misjudged by traditional algorithms), we deeply integrated this process into the decoder stage, extracting the energy decay waterfall corresponding to the native PCM sample rate. This allows the system to intelligently and accurately prevent issues before the user decides to write the tags.
Conclusion
Through these two core channels, the AI Music Organizer ensures local data privacy while pioneering a path of performance and safety for tag metadata analysis. In the upcoming technical analysis series, we will also dive into the underlying retrieval engine and the multi-language semantic architecture, so stay tuned.